

新たなデータセットの概要
この新しいデータセットは、Qlean Datasetが展開する機械学習用データセットラインナップ「AIデータレシピ」に加わるものです。レジャー、趣味、娯楽をテーマに、2名の話者が対話形式で語り合う日本語音声と、その発話内容を書き起こしたトランスクリプトが収録されています。具体的には、ドラマやアニメの感想、ゲームやガジェットのレビュー、旅行や外出の体験談など、日常的な話題に基づいた会話が含まれています。
収録は台本に依存せず、自然な流れでの感想や意見交換を前提としており、実際の会話シーンを想定した音声認識や対話処理などのAI研究・開発に適しています。
データセットの詳細
| データ種別 | 音声、テキスト |
|---|---|
| 被写体属性 | 20代〜50代の男女 |
| データ形式 | 音声データ:mp3 / wav、テキストデータ:txt |
| 収録時間 | 計約400時間(1音声約5分〜60分) |
| 音声レート | 44.1kHz |
| 対象のシーン | ・2名が趣味・娯楽テーマについて、連続的に説明・解説・振り返りを行うシーン(作品へのコメント、ゲーム・ガジェット等のレビュー、旅行・外出等の体験談など) ・体験談や感想を交えながら自由に会話が展開される場面 |
| サンプル詳細 | https://qleandataset.visual-bank.co.jp/lineup/pn-018 |
ユースケースイメージ
このデータセットは、研究用途と産業用途の両面で活用が見込まれています。
【研究用途】
-
日本語対話音声認識モデルの検証: 複数話者が対話するASRモデルにおいて、話者の切り替わりや応答関係を含む発話の認識精度検証に利用できます。
-
対話文脈を考慮した言語モデル研究: 話題の展開や相互参照を含む日本語対話テキストを用い、LLMや対話モデルにおける文脈理解や応答生成の挙動を評価する研究に役立ちます。
【産業用途】
-
音声UI・対話型AIの検証用途: 音声アシスタントや対話型インターフェースの開発において、日常会話に近い日本語対話音声を用いた入力処理や対話制御のPoC検証に利用できます。
-
日本語LLMの対話性能評価・追加学習: 業務会話に限定されない対話テキストを用い、日本語LLMにおける自然な応答生成や対話継続性の評価、ファインチューニング用途に活用できます。
Qlean Datasetについて
Qlean Datasetは、Visual Bank傘下の株式会社アマナイメージズが提供する、商用利用が可能なAI学習用データソリューションです。画像、動画、音声、3D、テキストなど多様な形式のデータに対応し、研究用途から商用開発まで安心して利用できる環境を整備しています。
株式会社千葉ロッテマリーンズや株式会社東洋経済新報社などのデータパートナーとの協業を通じて、業界特化・最新トレンドに即したデータラインナップ「AIデータレシピ」を継続的に拡充しています。Qlean Datasetは、AI開発現場でのデータ収集・整備の負担を軽減し、権利がクリアで法的リスクのないAI開発環境の構築を支援します。
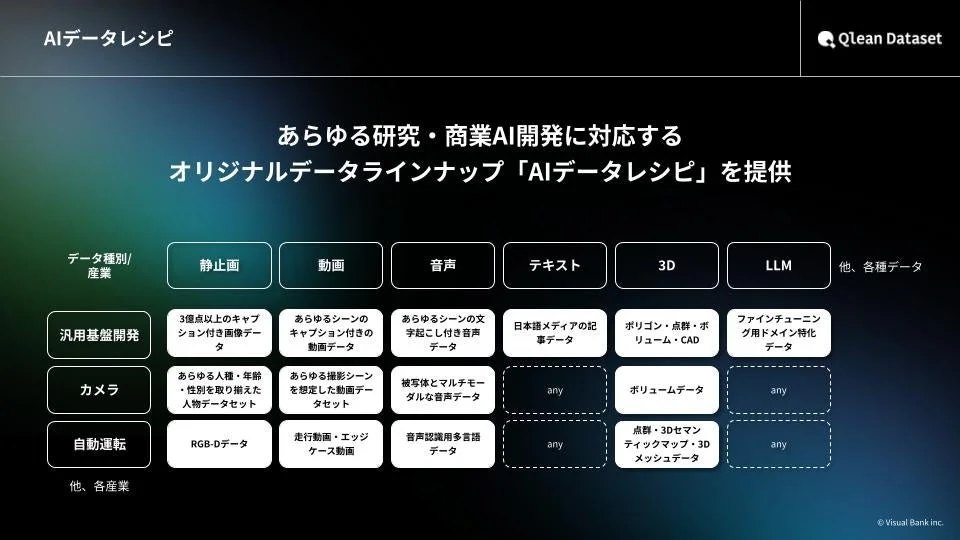
「AIデータレシピ」の主な特徴
-
すべての被写体から同意を取得しています。
-
既存データは最短1日で納品可能です。
-
カスタム撮影・収録・収集による独自データの構築にも対応しています。


Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業です。漫画家向けのAI補助ツール「THE PEN」や、AI学習用データセット開発サービス「Qlean Dataset」を提供する株式会社アマナイメージズを100%子会社としています。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、社会実装に向けた取り組みを加速させています。
-
Qlean Datasetサイト: https://qleandataset.visual-bank.co.jp/
-
Visual Bank企業URL: https://visual-bank.co.jp/
-
アマナイメージズ企業URL: https://amanaimages.com/about/

